Idea
The idea is to make a searchable list of what I have read, viewed , listen, given advice about in past.
This is going to have only technical content, this little book should ideally become better with time. A metric for the book's quality can indirectly also indicate myself becoming a better engineer or it could just be a better reader/scraper of internet, but we will see that in a while (Starting this on a good morning of 10 September 2023, A good checkpointing would be towards the end of the year.)
Making it open for multiple reasons, typically->
- Ignite more curiosity than anything else.
- People stumble upon this and suggest me better ways to learn
- Potentially stumble upon a mis understanding of an article/concept/topic/anything-else and correct me.
- Motivate me to read(more?) or complete the book to the very end(maybe?).
- Can save some time for myself (and readers?) when look at the gist of a certain topic and potentially
ring a bellin a particularly problematic scenario which otherwise wouldn't have. - Others can also benefit from
- The summaries.
- Ignite more curiosity.
- Find better places to find answers.
Goal
Goal of the book is not to re-write the entire blogs, books(other), transcripts, but rather concise summary of what I learnt and took away from them. In no way it is to dis-respect the original creator of the content or to steal their work. But, in past I have observed it's particularly hard for me to remember things I don't use everyday (but can come handy in certain situations), and this is just an attempt to solve that issue after root causing it to be lack of concise searchability.
Organization
The book is written using mdbook and so, it has a side navigation bar where the specific topic can be searched for and there is a searchable option as well in case the side bar isn't very helpful.
The book will be subcategorized broadly into few sections, and they will have pages (more?) as I keep stumbling more on their respective content.
These are broadly 4 different categories because I feel they are distinct enough in -
- How the content should be consumed
- How they are written and eventually how the summaries of them should be written.
- For example-> A blog is supposed to be pretty short(some exceptions for example-> fasterthanlime but for just that case it can be a subcategory inside articles) as compared to a paper for example.
Hopefully the introduction gets better too, but this is probably all I have as of now.
Blogs
Reading files the hard way
Books
Database Internals
Why I am reading this book?
To dive deeper into the database systems and have a hands-on in systems programming and write an end to end database system.
Intro
Database systems usually comprise of->
- Transport Layer
- Accepting requests from the clients.
- Query Processor
- Figures out the most optimal way to perform the asked query.
- Execution Engine
- Take plan from the query optimizer and aggregate remote and local execution results.
- Storage Engine
- stores, retrieves, and manages data in memory and on disk, designed to capture a persistent, long-term memory of each node
These systems are usually build independent and in isolation with some variants of a DBMS tightly coupling few or all of the modules because of performance reasons (saving allocations/thread creation on hot path etc.). But usually any combination of them can result in a new variant suitable for some specific type of workload/usecase or data storage.
Storage Engines
Storage engines actually store the data on physical memory or disks and provide simple APIs to access and manipulate it. The DBMS supporting complex queries is just a fancy parser applications built on top of storage engines, and can provide more capabilities like Schema, Query Language, Transactions etc.
Databases are an important piece of software for most applications, and hence has potential to have long term consequences. Each database was designed while keeping one thing or one set of things in mind. It's always the beginning when it's best to find if a certain database will not be a good fit because of performance, consistency, etc reasons. Since, not everyone can afford to perform rigorous testing of multiple databases to evaluate the best one for their requirements, there are other platforms which can provide with high level semantics for the usual benchmarks(YCSB) which can be retro-fitted in most cases to the exact requirements.
These should be used with caution since it's easy to draw a premature/invalid conclusion without looking at the data extensively and without listing down the requirements first.
But performance is often not the only criteria to choose a database system for a long run. Since programming is as much a human construct as it is a machine's. Considering software being programming integrated over time, the familiarity, ease of debugging, pain of upgradation, community around it are often the equally important factors if not more.
Past smooth upgrades do not guarantee that future ones will be as smooth, but complicated upgrades in the past might be a sign that future ones won’t be easy, either. Any usual 3rd party software decision.
Difference from a programming problem
Any sufficiently complex piece of software is very different from a standalone programming problem. Databases differ in ways->
- Design physical layout.
- Organize pointers.
- Decide on serialization format.
- Dead tuple/data garbage collection schemes.
- Making it work in concurrent environments.
- Data Durability guarantees.
-> Chapter 1
There are a lot of buckets databases can be categorized into, based on->
- How they store the data.
- Where they store the data.
- Usage purposes.
- Different query supports.
- What kind of data they need to optimize for storage.
- etc..
DBMS Architecture
- OLTP Databases-> Handle large number of user facing requests and transactions. Short lived queries returning small sets of data.
- OLAP Databases-> Handle complex aggregation over multiple data sets(tables, collections, documents etc.), Long running low number of queries returning large sets of data.
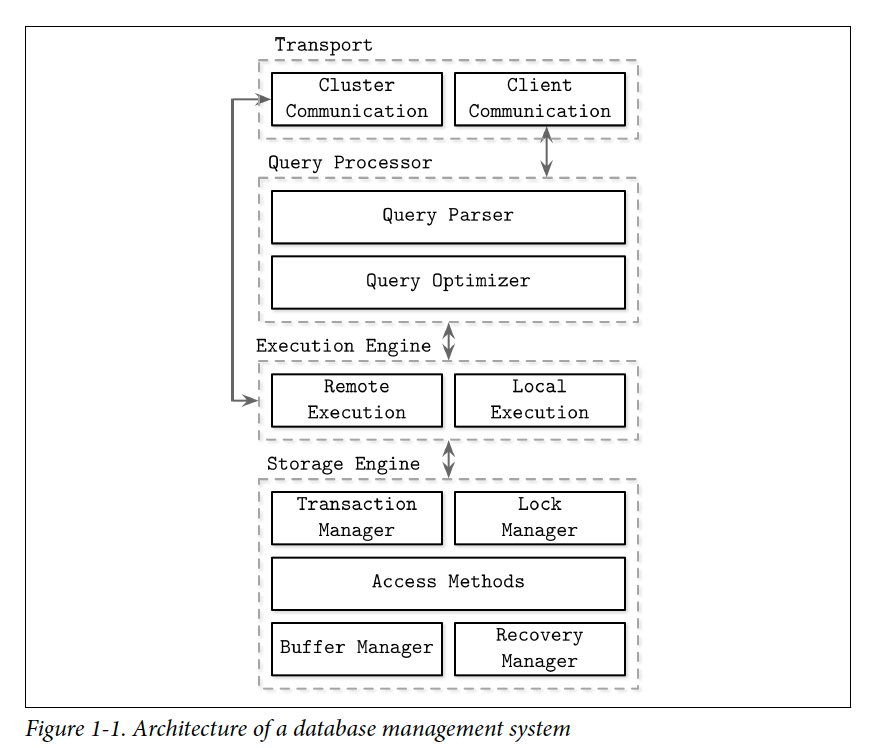
Transport Layer
Handles the client request receival and intra node communication. The intra node communication is handled differently in most database systems because of the redundant steps like access control and query validation checking which can be avoided for better throughput and latency requirements.
Query Processor
Handles the query vetting part-> parsing, interpreting, validating, access control checks etc.
Query optimizer
Eliminates impossible and redundant parts of the query, find the most efficient way to perform the asked query based on internal data and statistics. (Index cardinality, approximate intersection size, data placement (in distributed systems scenario which nodes hold the data and cost associated with the transfer etc.)). Handles optimizations such as-> index ordering, cardinality estimation etc.
Execution Engine
The responsibility mostly is to accept the query path/execution plan from the query optimizer and perform remote execution(call other node's transport layer) or local execution(which is just using the actual storage layer now) and aggregate the results from both the executions.
Storage Engine
- Contains the transaction manager to ensure the transactions ordering can't leave the database in a logically inconsistent state.
- Contains lock manager to support the transaction manager, ensuring the concurrent operations don't violate physical data integrity.
Transaction + Lock Manager together help in concurrency control.
- Access Methos contain the actual data accessing by leveraging the properties of the storage structures used while storing the data.
- Buffer Manager caches data pages in memory for faster lookups of the similar subsequent queries.
- Recovery Manager maintains the operation log and restores the system state in case of a failure.
TODO: Transaction Manager should reside in storage engine because that's where the data is actually stored and protecting it's integrity should lie within the storage engine, a poorly designed/created query processor shouldn't compromise the physical data integrity, but should it be the same for distributed databases as well? Or should there be two levels of transactions control one above the storage engine(probably at query processor?)
Memory vs Disk Based Arch
- Memory-> Store data primarily in memory and use disk for logging and recovery. Programming is simpler, OS abstraction helps to with memory management and allows to think in terms of freeing arbitrary sized memory chunks. Uses WALs(Write Ahead Logs) for persistence and data durability since the memory is volatile. Checkpointing(Creating data snapshots from WALs in batches) + log files are used to recover the last known state of the memory DBs.
- Disk-> Stores data mostly on disk and use memory for caching for lower latencies. Programming is harder, and have to manage the data references, serialization formats and fragmentation manually.
Since the pointers are easily followed in RAM(random and sequential memory access is both 0.5), which isn't same for disks(they have to seek, and can potentially require multiple seeks (random and sequential have different costs associated for disks(SSD and HDD both))), memory DBs allow for a greater pool of data structures to be utilized in comparison to what's possible for disk based DBs.
Columns vs row oriented Datastores
The difference is how the data is stored, spatial locality comes into picture and the decision is mostly based on how the data access pattern is (co-located data accessed frequently).
- Column Oriented-> Data for different columns are stored in different files/segments. Useful for aggregation. Since the data is stored column wise, an additional metadata is required to figure out which other column's data it is associated with. Reading multiple values for the same column in one run significantly improves cache utilization and computational efficiency. On modern CPUs, vectorized instructions(SIMD(Single Instruction Multiple Data, performing same operation on multiple data points)) can be used to process multiple data points with a single CPU instruction. Storing similar types together(as with the same column) allows for better compression ratio.
Considering all the advantages column DBs provide, the access pattern is still the dominant factor in deciding which one to choose from this category.
Data Files and index files
Most often than not, a database will have an index(which are just auxillary data structures to avoid entire table scans on each access and efficiently locate the data) for lookup, otherwise the query time for even a simple query would take a very long time.
- Data Files-> store the actual data records(serialized), can be implemented as index, hash, heap organized.
- Hashed Files-> hash value of the key determines the bucket for the record. The bucket size are usually small, and the data is inserted in the append only fashion or sorted by their ASCII or UTF8 values.
- Heap Organized-> Additional index structure is required, pointing to locations where data records are stored to make it searchable.
- Index Organized-> Data records stored in the index itself. Range scans can be implemented by sequentially scanning the index file's contents itself. They reduce the disk seeks by atleast once while accessing, but has a lot of overhead while inserting the data, also a very big file to search for, and disk seeks are more required because the data is stored in the same block, making the other data in a very different block. Clustered by definition.
- Index file-> stores the metadata about the data which is usually just a very little information -> the file, segment and the offset. They also don't contain all the fields(search keys), but a subset of them, and use some property to figure out the location of the required key from the spatial data like lexicographic sorting etc.
Usually the data and index files are different. Files are partitioned into pages, which are typically the size of some multiple of disk blocks. Deletions and updations are performed by tombstoning in most cases the spaces for which(shadowed records/non live) are claimed by the next GC cycle.
-
Clustered Index-> When the order of data records follow the search key order. Data records are usually stored in the same file or in a clustered file(Virtual pointing to multiple files). Table records are physically reordered to match the index.
-
Non Clustered Index-> Physical data records order is independent of logical records of index.
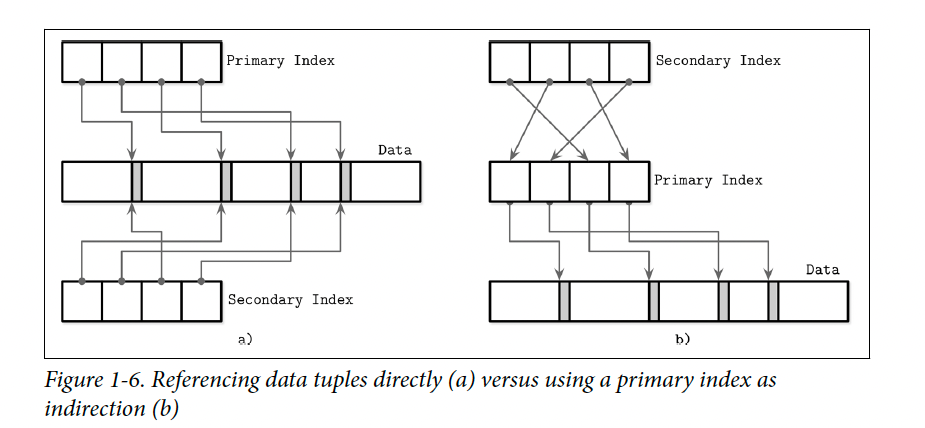
Primary Index as indirection
A lot of the times you won't just have one primary index but multiple other secondary indexes as well to allow for different lookup patterns based on different fields. Each index can either store the metadata about the data record(data file), or can reference the primary index. Since the metadata has a fixed overhead, the primary index's reference/location won't change even though the record has grown or shrunk, but overheads an extra seek. So, if the application is very read heavy, first approach can be used, else second approach will be beneficial in most cases. Hybrid approach can also be used at the expense of more storage overhead, where the secondary indexes data record reference can just be invalidated in sync, while the async workers repair that invalidated reference.
Buffering, immutability and ordering
Storage engines use some data structure. However, these structures do not describe the semantics of caching, recovery, transactionality, and other things that storage engines add on top of them.
All the structures have the variants of the form-> use buffering(or not), use immutable(or mutable) files, stores values in order(or out of order).
- Buffering-> Whether a certain amount of data should be buffered to memory before flushing it to disk. This buffering is different than just a single block buffering(because that is used by all variants of disk DBs.), it's mostly about avoidable buffering to amortize the I/O costs and increase the throughput.
- Mutability-> Whether or not the structure reads parts of the file and writes the updated result in place. LSM are mostly immutable while BTrees are in place update structures though with some variants of B Trees holding immutability property.
- Ordering-> Whether or not the data records are stored in the key order in the pages on disk. Keys that sort closely (for some definition of sorting) are stored in contiguous segments on disk. Ordering allows for efficient scanning, while writing out of order optimizes for write time speed, since it's hard to impossible to beat the throughput and latency of an append only file.